
우선 힙 트리를 알고 가야한다.
출처: 동빈나
힙 트리
힙 트리는 트리 자료구조에서 자식노드보다 부모노드가 큰 상태를 뜻한다.
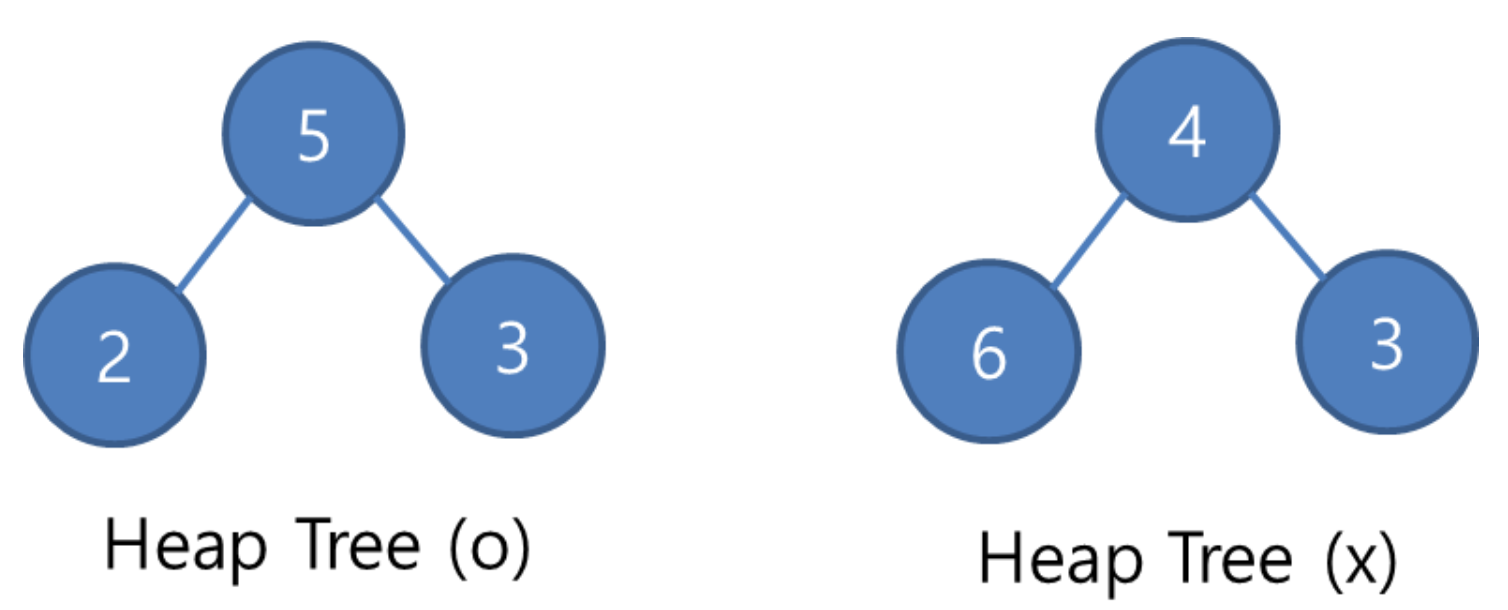
최대힙과 최소힙의 다른점은 점점 내려갈수록 값이 커지는가, 작아지는가 차이지만 모두 균일성을 유지해야 한다.
완전 이진트리
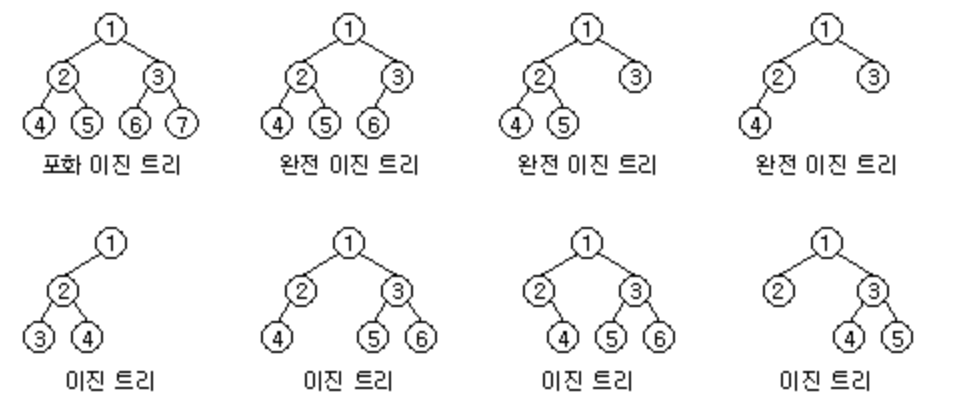
완전 이진트리는 왼쪽부터 채워나간다.
완전 이진트리는 배열에 넣게되어도 유휴 공간이 발생하지 않는다.
아래와 같은 이진트리가 있을경우
A번 노드부터 L번 까지의 노드에 번호를 매긴다면 아래와 같다.
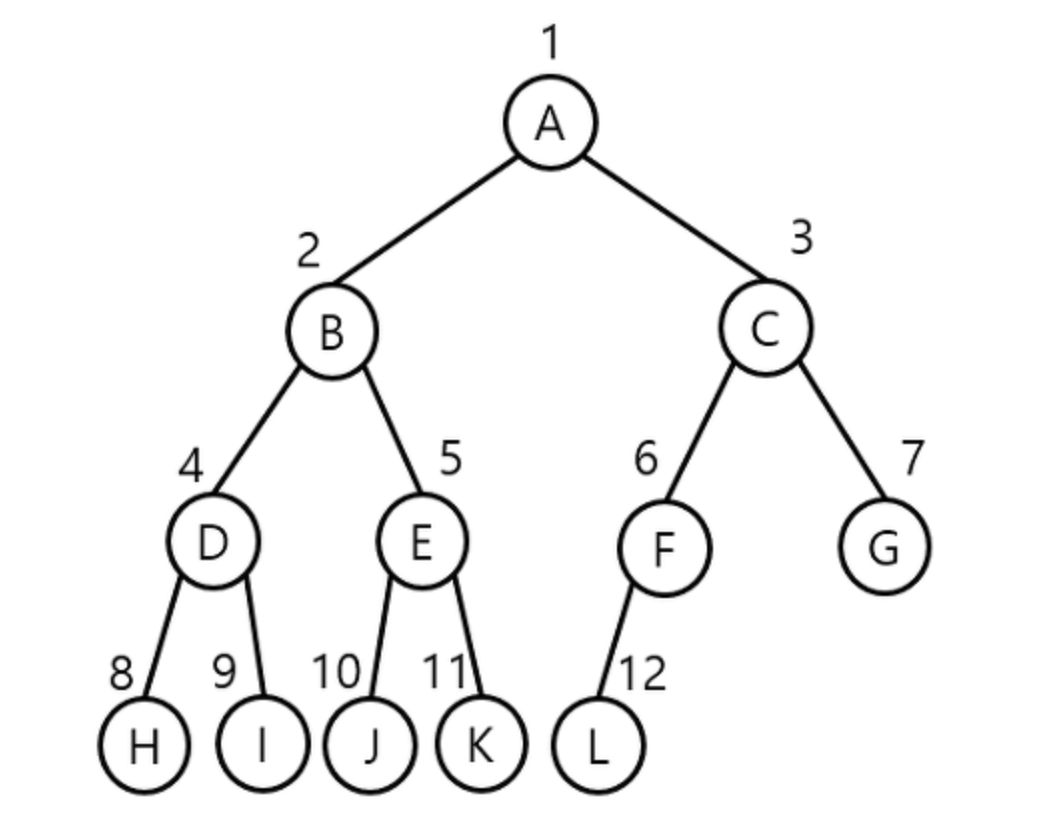
이를 보고 추리한다.
n노드의 부모 -> n / 2 (나머지는 버림)
n노드의 왼쪽 자식노드 -> n * 2
n노드의 오른쪽 자식노드 -> n * 2 + 1
heapify
heapify는 하나의 노드에 대해 수행한다.
자식노드와 자신을 비교해 자식노드에 더 큰 수가 있다면 자식노드와 자신의 위치를 바꾼다.
또 자식 노드와 교환이 이루어진 이후에도 여전히 자식 이 존재하는 경우 또 두 자식중에서 더 큰 자식과 자신의 위치를 바꾸어야 한다.
또한 힙구조로 만들기 위해선 heapify를 n/2번 만큼만 수행해주면 된다.
수행과정
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 값 | 7 | 6 | 5 | 8 | 3 | 5 | 9 | 1 | 6 |
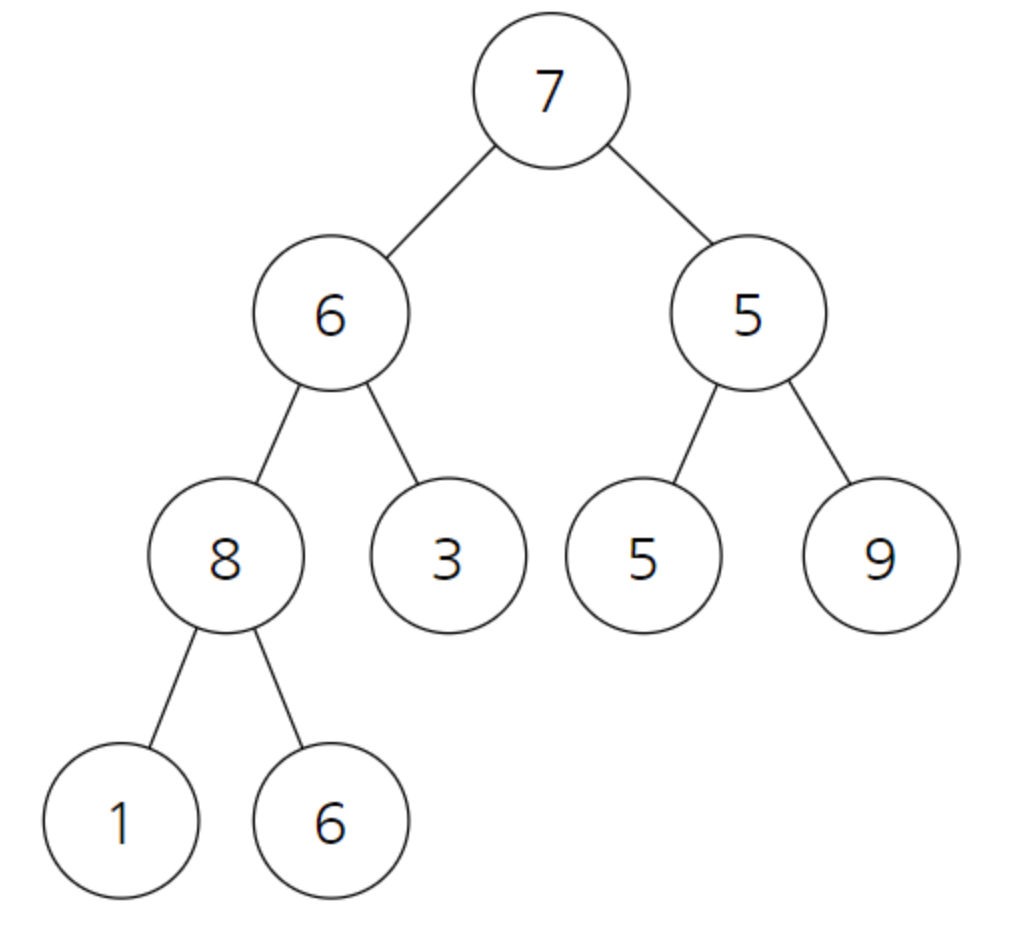
전체 힙 구조를 만들기 위해선 전체 노드의 개수의 n/2개 즉 9/2 = 4개만큼만 보면 된다
소수점 이하는 버림
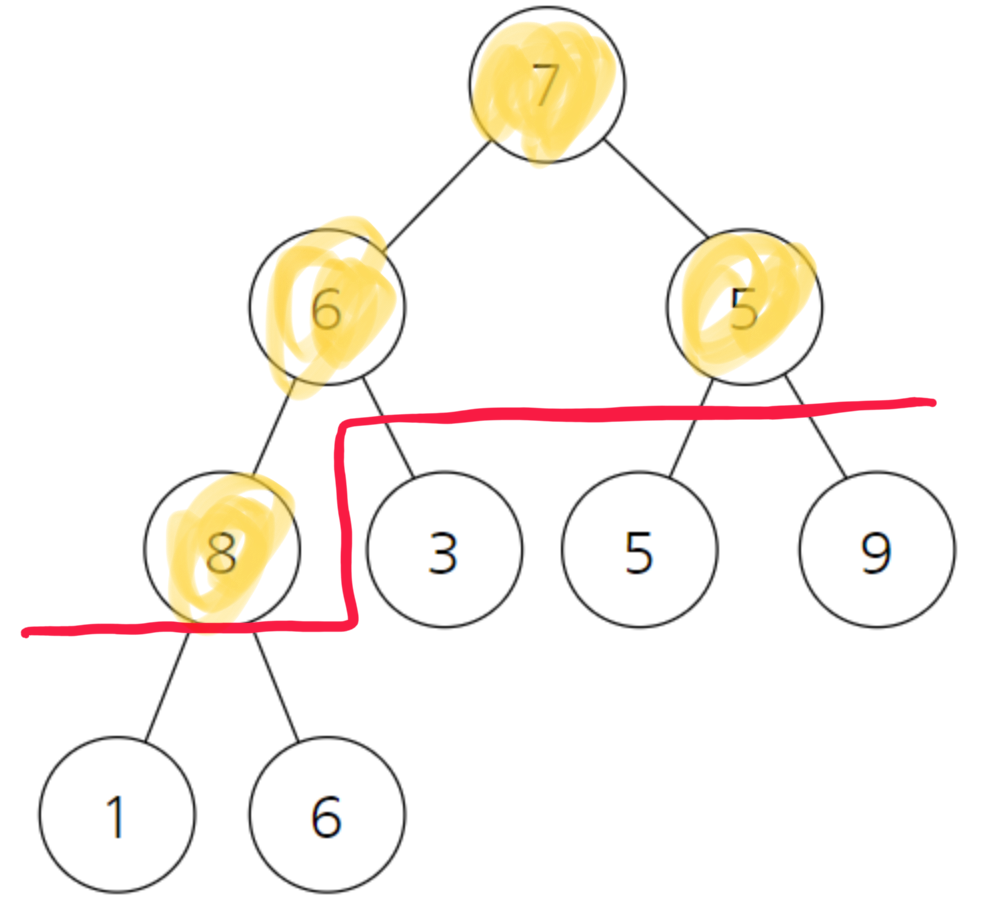
8은 자식인 1과 6보다 크다.
5의경우 자식인 5와 9를 봤을때 9가 더 크다 자리교환이 일어난다.
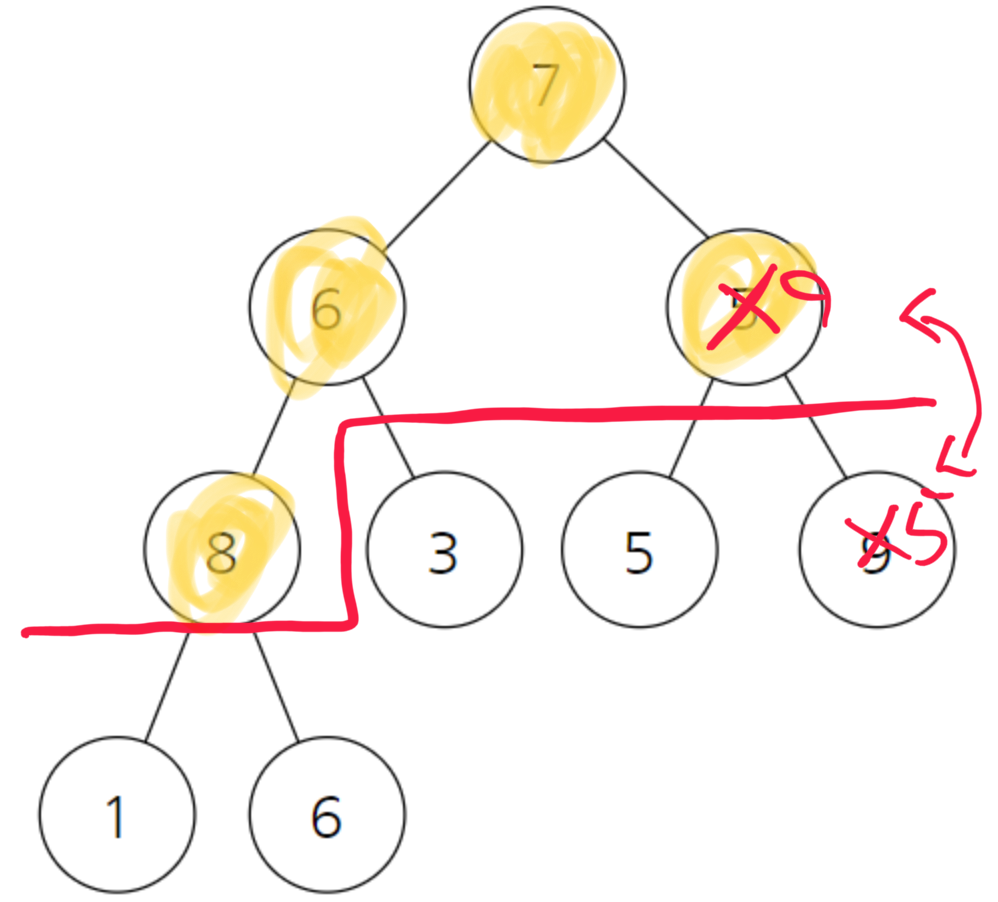
또 9를 기준으로 봤을 때 7보다 9가 크다. 자리교환이 일어난다.
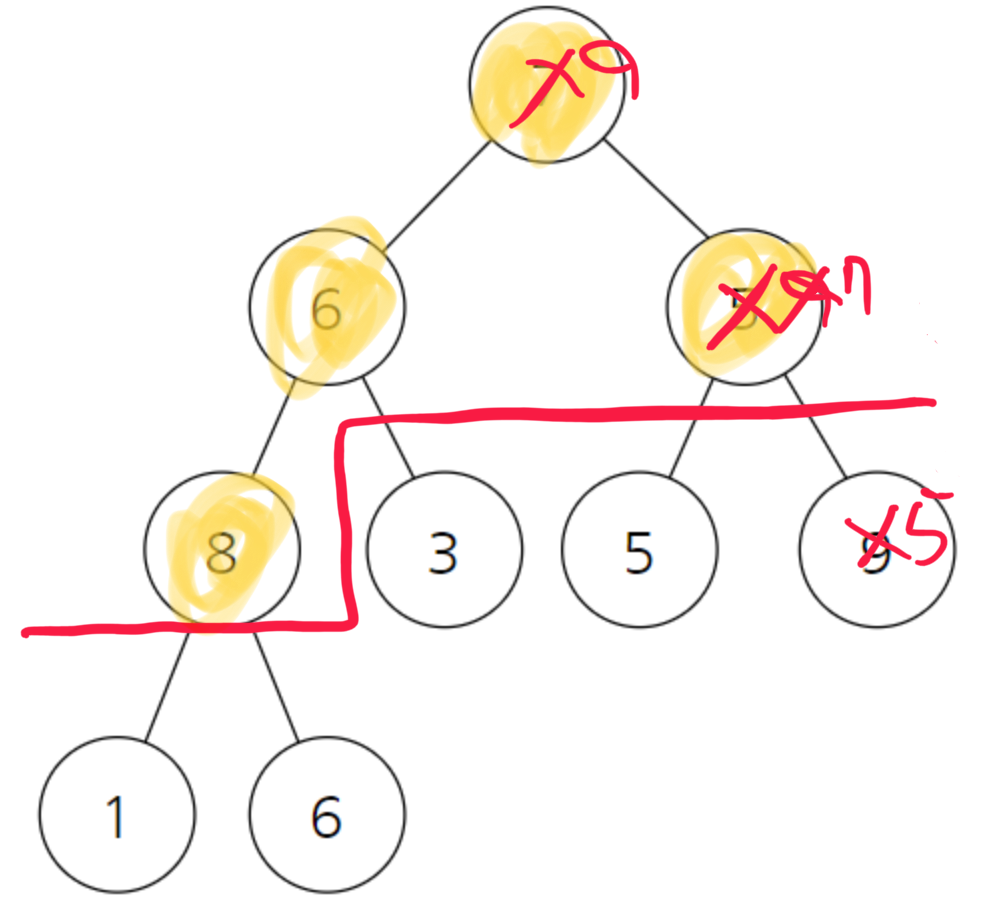
6을 기준으로 본다 8보다 작기 때문에 자리교환이 일어난다.
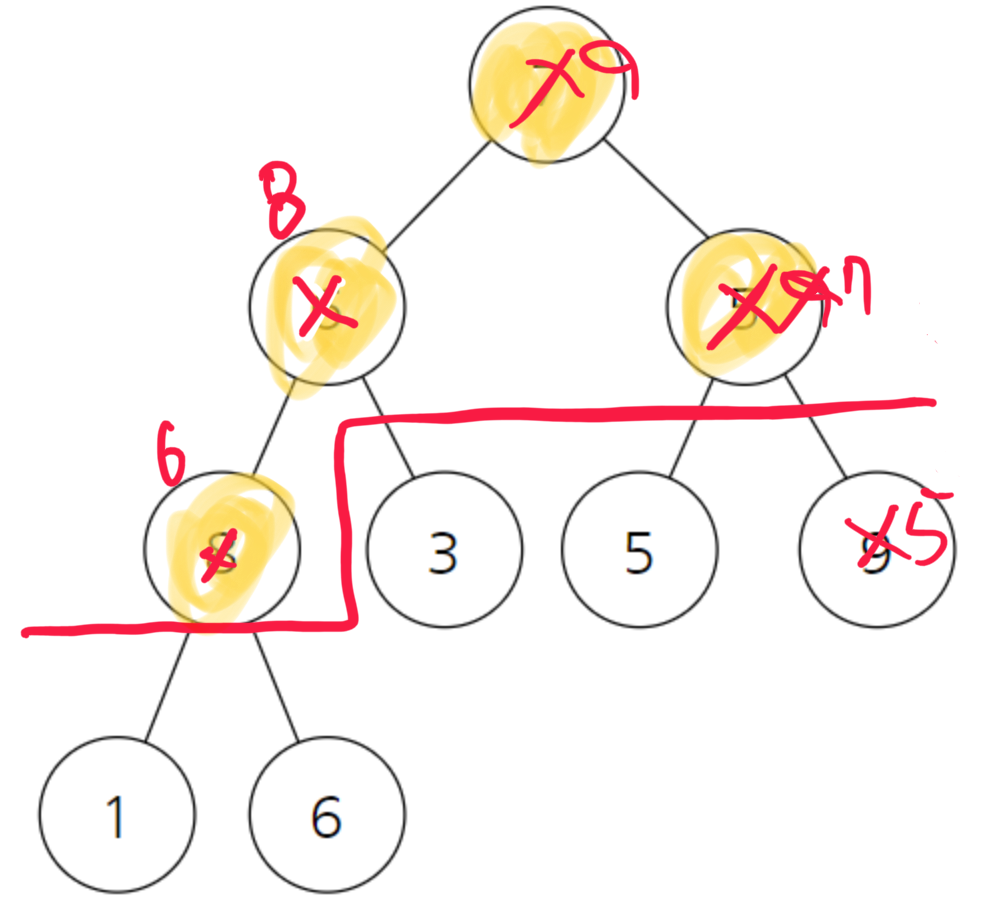
8과 9를 비교해서 8이 9보다 작기 때문에 상관없다.
9는 8과 7보다 크기때문에 상관없다.
힙 구조가 만들어졌다.
이는 상향식으로 힙 구조를 만든 것으로, 아래의 하나의 힙부터 시작해서 점차 위쪽으로 올라가며 힙 구조를 만들었다.
반대로 아래쪽으로 내려가는 식으로도 만들어도 무방하다. 이는 프로그래머의 마음이다. 비교할 필요도 없다.
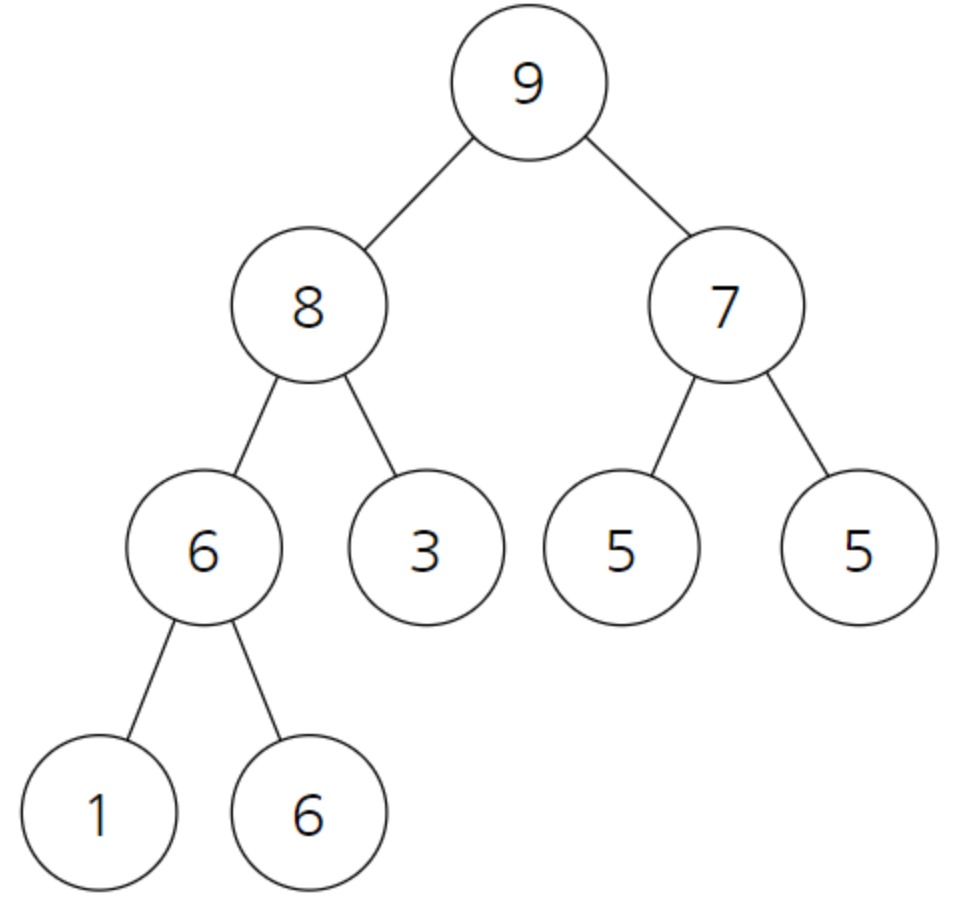
이렇게 힙 구조가 만들어 졌다고 하면, 특정한 반복 작업을 진행해준다.
루트노드엔 가장 큰 값이 들어있다 이를 가장 마지막 원소와 바꾸어 주는 것이다.
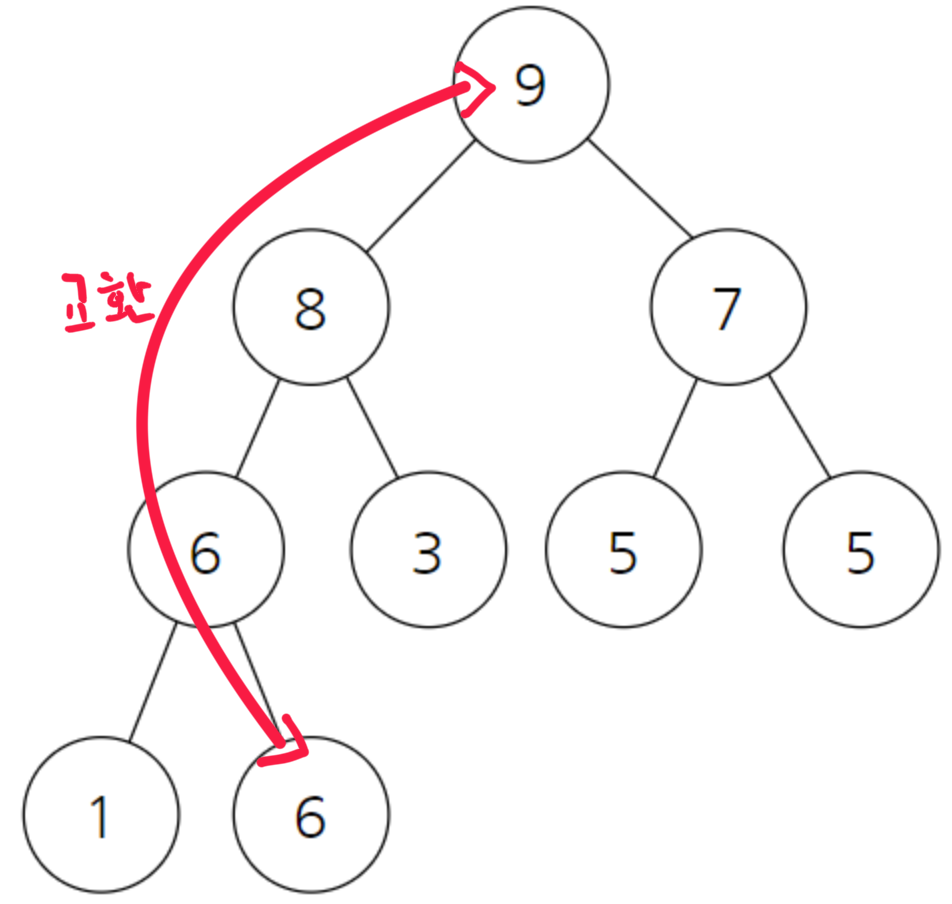
이렇게 되면 가장 큰 원소는 맨 마지막 원소로 들어가게된다. 고로 집합의 크기를 하나 줄여서 해당 부분만 본다.
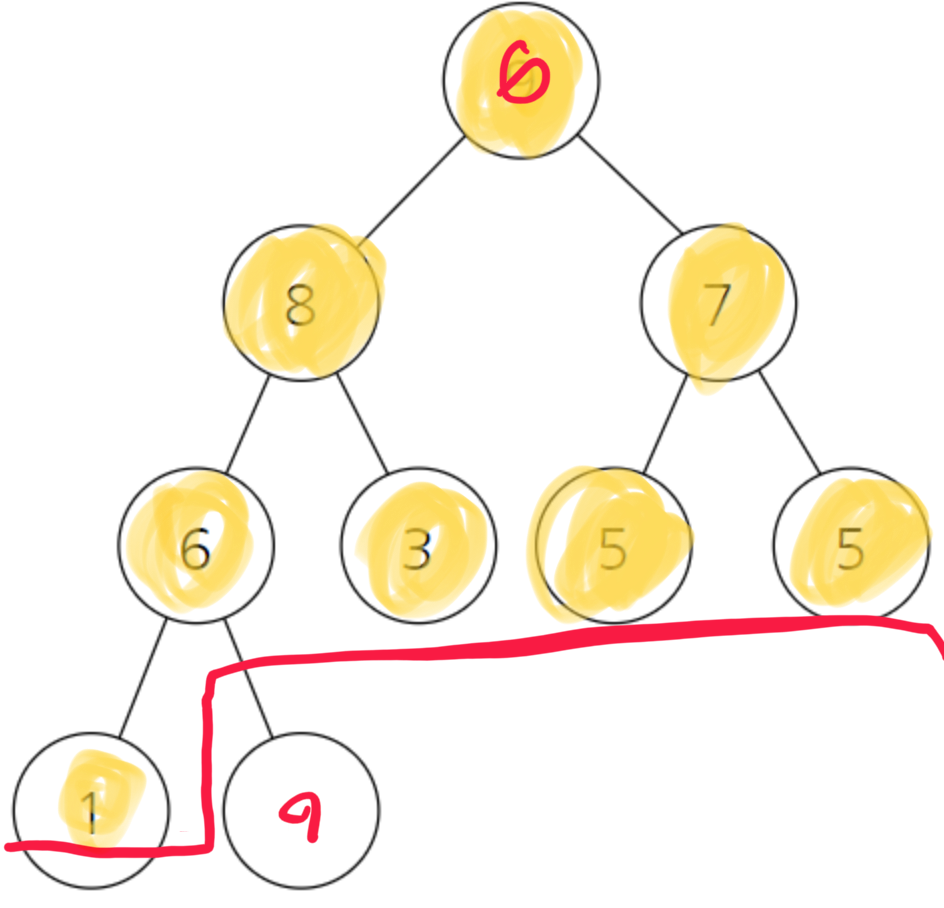
이제 다시 힙 구조로 만들어 준다. 6에서 출발을 해서 자기 자식이 더 크다면(두 자식중 더 큰 수) 자리를 바꿔준다.
그럼 아래처럼 6과 8의 위치가 바뀔 것이다.
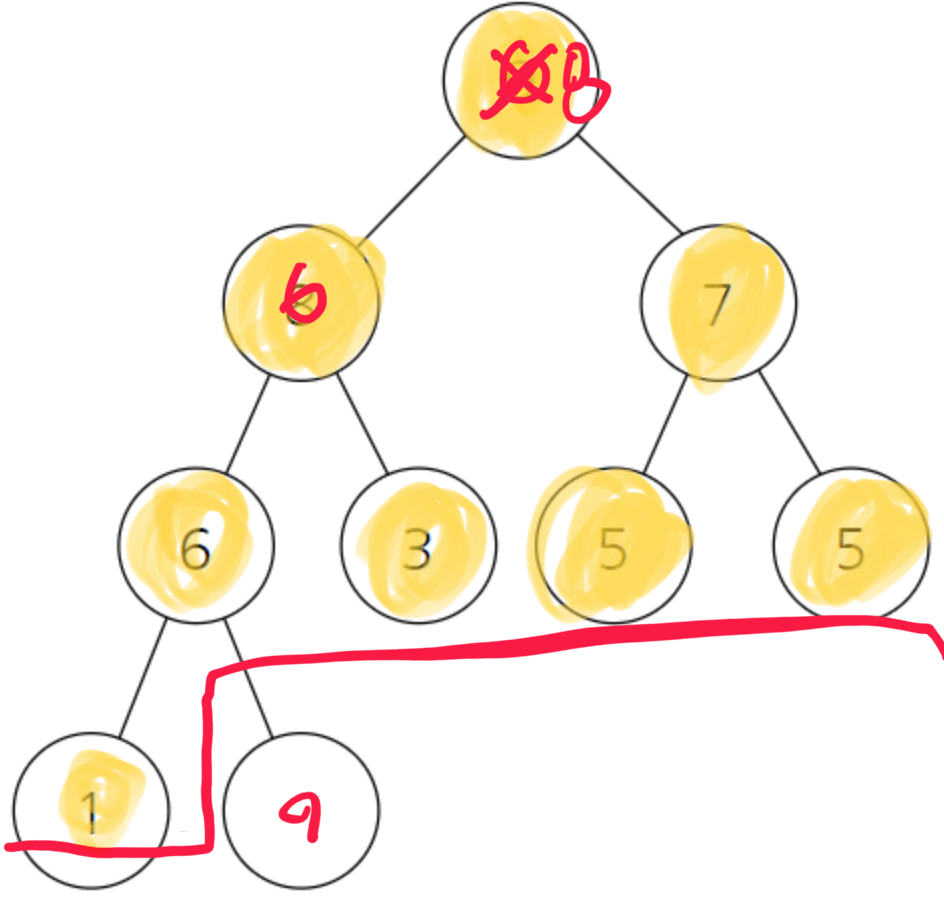
그럼 다시 8을 집합의 마지막 부분으로 보내서 1과 바꿔주고, 집합의 크기를 하나 줄여서 해당 부분만 본다. 그렇게되면 이런 모양일 것이다.
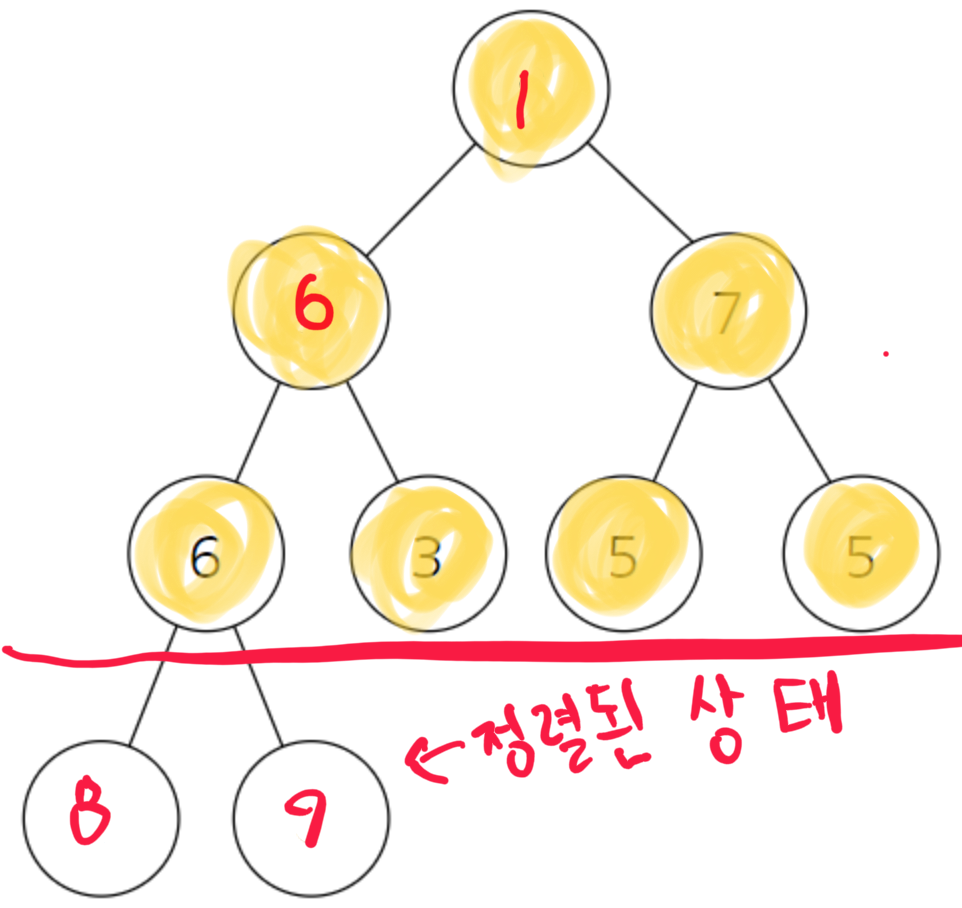
1. 힙에서 가장 위에있는 값을 뺴서 아래로 옮겨준다.
2. 다시한번 heapify를 수행한다.
1번과 2번 작업을 반복해준다.
시간복잡도
한 개의 원소를 기준으로해서 힙을 만드는 시간복잡도는 log n밖에 안된다. 힙을 들 때에는 트리의 높이 만큼만 계산하면 된다.
고로 heapify의 시간 복잡도는 log n이다.
이 heapify를 반복하는 횟수는 전체 원소의 개수만큼이다.
원소의 개수만큼 반복하면 정렬이 이루어진다.
전체 시간복잡도는 O(N * log N)이 된다
코드
void heapsortt(Double data[], int heap_size)
{
int k,i;
for (i = (heap_size - 1) / 2; i >=0; i--)
downheap(data, i, heap_size);
for (k = heap_size -1; k > 0; k--) {
SWAP(data[0], data[k]);
downheap(data, 0, k);
}
}
void downheap(Double data[], int cur, int end)
{
int left, right, p;
left = cur * 2 + 1;
right = cur * 2 + 2;
if(left >= end) return;
p = left;
if (right < end) {
if (data[p] < data[right]) p = right;
}
if (data[cur] < data[p]){
SWAP(data[cur], data[p]);
downheap(data, p, end);
} else
return;
}
실행 결과
해당 자료는 랜덤한 데이터를 만들어서 처리한 결과이며, 시스템에 따라 다를 수 있다.
| 자료 개수 | 처리시간(Insertion sort) | 처리시간(Shell sort) | 처리시간(Heap sort) |
| 10000 | 0.000374 | 0.00125 | 0.006490 |
| 100000 | 0.003652 | 0.018056 | 0.053102 |
| 1000000 | 0.021501 | 0.179746 | 0.640039 |
| 100000000 | 2.292645 | 21.730830 | 112.782890 |